KMP 알고리즘은 문자열 A와 문자열 B가 있을 때, 문자열 A에서 문자열 B를 찾아주는 알고리즘 입니다.
KMP는 KMP를 만든 사람의 이름인 Knuth, Morris, Prett 세 사람의 앞 글자를 따서 KMP 알고리즘이라고 불립니다.
자 그러면 우리는 문자열 A에서 문자열 B를 찾는 방법을 생각해봅시다.
가장 먼저 생각해 볼 수 있는 방법은 Brute force가 있겠군요.
하지만 모든 경우를 다 탐색할 경우 문자열 A의 길이가 N,문자열 B의 길이가 M이라면 O(N*M)의 시간 복잡도를 가지게 됩니다.
만약 N,M이 10만인 문제가 주어진다면 시간 초과를 보게 될 것입니다.
자 그러면 KMP를 사용하였을 때의 시간복잡도는 어떻게 될까요?
놀랍게도 O(N+M)의 시간복잡도만에 문자열 A에서 문자열 B를 검색 할 수 있습니다.
자 그러면 KMP는 어떤 방법으로 O(N+M)의 시간복잡도에 문자열 검색이 가능한 것일까요?
다음과 같은 예를 들어봅시다.
문자열 A= ABABBABABCABB
문자열 B= ABABC

brute force를 이용한다면 다음과 같이 매번 대응시켜서 같은지 확인하여야 할 것입니다.

하지만 다음과 같이 첫번째 비교 때 4번째 문자까지 같다는 점을 이용하여 두번째 비교를 건너 뛰고 세번째 비교로 넘어가는 방법이 있다면 시간을 대폭 줄일 수 있을것입니다.
자 그러면 우리는 어떻게 현재 비교중인 문자열에서 K번째 문자까지 같다는 점을 이용하여 비교를 건너 뛸 수 있을까요?
KMP에서는 문자열을 비교하다가 찾는 문자열과 다르다는걸 알게 되었을 때 실패 함수(failure function)라는 값을 참고하여 다음 비교 위치를 정해줍니다.
그러면 실패함수(failure function)은 어떻게 정의되고 어떻게 참고하여 어떻게 건너뛰게 될까요?
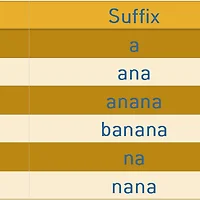
실패함수(failure function) pi[x]의 정의는 검색하려는 문자열 B의 0번째~x번째 위치까지 볼 때 접두사(prefix)==접미사(suffix)가 되는 최대 접두사(or 접미사) 길이입니다.

위의 표는 검색하려는 문자열 B=(ABABC)의 pi배열(failure function)을 나타낸 것 입니다.
이제 pi배열에 대한 정의가 와닿나요? 몇가지 예를 더 들어보겠습니다.
예를 들어 ABCBA라는 문자의 pi[4]는 1이 될 것입니다. AB !=BA이기 때문입니다.
그러면 AKAKA라는 문자의 pi[4]는 1일까요?
아닙니다 절반을 넘는경우도 세줍니다.
AKA==AKA이기 때문에 pi[4]는 3이되겠군요.
자 저희는 이 pi배열을 이용하여 어떻게 비교를 건너 뛸 수 있을까요?
우리는 문자열 A=ABABBABABCABB 에서 B=ABABC를 찾을 때
첫번째 비교에서 ABAB까지 즉 문자열 B의 3번 인덱스 까지 같다는걸 알고 있습니다.
그러면 우리는 현재 4번째 인덱스를 보고있습니다. 이때 원래 비교에서의 prefix인 AB와 내가 현재 보고있는 인덱스 바로 전 인덱스부터의 suffix인 AB가 같다는 걸 알고 있으니 우리는 이미 현재 위치에서 AB까지의 탐색이 완료됬다고 생각해도 됩니다.
따라서 AB/ABC <= 문자열 B에서 2번 인덱스인 A인지 확인해주면 됩니다.
좀 더 쉬운 이해를 위해 코드를 보겠습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | void kmp(){ int j = 0; for (int i = 0; i < a.length(); i++){ while (j > 0 && a[i] != b[j]) //현재 j만큼 찾았는데 이번에 비교하는 문자가 다른 경우 j = pi[j - 1]; //문자열 B를 failure function 이후 부터 비교를 해줍니다. if (a[i] == b[j]){ //비교하는 문자가 같은 경우 if (j == b.length() - 1){ //문자열 B를 전부 탐색하였기 때문에 답에 위치를 넣어줍니다. res.push_back(i - b.length() + 1); j = pi[j]; //다음 탐색을 위하여 이번에도 failure function 이후 부터 비교를 해줍니다. } else j++; //문자열 B의 다음 단어를 비교해줍니다. } } } | cs |
코드를 잘 보시면 답을 찾은 경우에도 j를 pi로 갱신하는데 이유는 우리는 문자열 B가 나오는 모든 위치를 탐색해야하기 때문입니다.
코드를 잘보시면 i의 값은 증가하거나 그대로이고 j의값만 pi값으로 유동적으로 변하는걸 알 수 있습니다.
따라서 우리는 A문자열을 한번 스캔하면서 B문자열을 어디서부터 비교할지만 계속 바뀌면서 탐색이 이루어진다는 걸 알 수 있습니다.
자 그러면 failure fuction은 어떻게 구해야할까요?
failure function을 구하는 아이디어는 신기하게도 KMP와 비슷합니다.
KMP 알고리즘을 수행하기 위해 필요한 failure function을 구하는 방법이 KMP와 비슷하다니.. 그렇기 때문에 KMP 코드를 먼저 공개한겁니다.
failure function을 문자열 B에서 문자열 B를 찾는다는 느낌으로 비교를해주면 됩니다.
편의상 같은 문자열 B를 A,B로 부르겠습니다.
우리는 문자열 A에서 문자열 B를 슬라이딩 시키면서 B의 prefix가 A의 일부와 같아질 때, A의 위치를 i B의 위치를 j라 할때 pi[i]=j로 갱신해줍니다.
이후 불일치가 일어나면 KMP에서 그랬듯 pi 배열만큼 j를 이동시켜줍니다.

다음과 같이 슬라이딩하면서 B의 prefix가 같아질 때 pi를 갱신해 준 뒤 j를 pi로 갱신합니다. j=pi[j-1]이므로 pi[1] 이므로 0으로 갱신되겠군요.
1 2 3 4 5 6 7 8 9 10 | void getpi(){ pi.resize(b.length()); int j = 0; for (int i = 1; i < b.length(); i++){ while (j > 0 && b[i] != b[j]) j = pi[j - 1]; //불일치가 일어날 경우 if (b[i] == b[j]) pi[i] = ++j; //prefix가 같은 가중치만큼 pi를 정해줍니다. } } | cs |
pi배열을 구하는 소스코드는 다음과 같습니다.
보통 KMP문제들은 단순히 문자열을 검색하는 문제가 나올 수도 있지만
failure function만 필요한 경우도 많기 때문에 잘 응용할 수 있어야합니다.
자 이제 KMP 알고리즘으로 다양한 문제를 풀어봅시다.
'알고리즘 관련 > 알고리즘&이론' 카테고리의 다른 글
| 이분 매칭(Bipartite Matching) (7) | 2017.02.12 |
|---|---|
| Suffix Array & LCP Array(Longest Common Prefix Array) (4) | 2017.02.08 |
| [자료구조]트라이(Trie) (4) | 2017.02.04 |
| 단절점(Articulation Point)와 단절선(Bridge) (1) | 2017.01.31 |
| [최장 증가 수열] LIS(Longest Increasing Subsequence) (33) | 2017.01.25 |